Episode 183: STS-93 - Sometimes It's Better To Be Lucky Than Smart (Chandra Deploy)
Table of Contents
On STS-93 we’ve got a ton of stuff to do in a mission lasting less than five days. We’ll break another glass barrier, we’ll put the redundancy of the Space Shuttle Main Engines to the test, and we’ll explore the universe in a whole new part of the spectrum. Buckle up, it’s a heck of a flight.
Episode Audio #
Photos #














For more photos, head over to our friends at Wikiarchives.space: https://wikiarchives.space/index.php?/category/606
Post-Flight Presentation #
Mission Control Ascent Audio #
In this audio, you can hear the ground’s reaction to the unfolding problems during STS-93’s ascent.
Wayne Hale Blog Posts #
I definitely recommend Wayne Hale’s blog in general, but especially his STS-93 posts which will add extra details and context to this episode:
- STS-93 and the Flight Director Office
- STS-93: Keeping Eileen on the Ground, Part 1
- Keeping Eileen on the Ground: Part II – or – How I Got Launch Fever
- Understanding STS-93: the key is Mixture Ratio
- STS-93: Dodging Golden Bullets
- STS-93: Dualing computers
- Practicing for Disaster
- STS-93: We don’t need any more of those
Transcript #
NOTE: This transcript was made by me just copying and pasting the script that I read to make the podcast. I often tweak the phrasing on the fly and then forget to update the script, so this is not guaranteed to align perfectly with the episode audio, but it should be pretty close. Also, since these are really only intended to be read by myself, I might use some funky punctuation to help remind myself how I want a sentence to flow, so don’t look to these as a grammar reference. If you notice any egregious transcription errors or notes to myself that I neglected to remove, feel free to let me know and I’ll fix it.
Hello, and welcome to The Space Above Us. Episode 183, Space Shuttle flight 95, STS-93: Sometimes it’s better to be lucky than smart
Before we start, I just wanted to mention for those of you who listen right as the episodes come out that you might want to take a look at the show’s website, thespaceabove.us. In the next week or so I’m going to be adding an “Updates” section which will be the place to check the status of episodes and just generally what’s going on. My thought was that not everybody cares about every twist and turn of the production schedule, but some people do, so this way they can seek it out if they want. Plus, by posting it online for all to see, I think it will help keep me more on top of the schedule in the first place. So keep an eye out for that. And if you haven’t seen the site before, it’s definitely worth a visit. I post a bunch of photos and extra goodies for each episode these days, so it can help add context or extra information. There are also episode transcripts if you can’t understand my rapid mumbling. Anyway, let’s get to it.
Last time, we talked about the first resupply mission to the International Space Station, STS-96. We transferred a bunch of equipment, deployed a student-built disco ball, and even learned a little video game history. The flight had been substantially delayed by the ongoing difficulties with readying the Russian ISS service module Zvezda for launch, and those difficulties still loomed large, resulting in this being the only flight to the ISS in 1999. So today, instead of looking forward to the future with the ISS, we’ll take a look back with a mission that feels very old school, and which will allow us to peer into the distant past of our universe.
The reason I say that this feels like a very old school Shuttle mission is that what you might think of as a typical Shuttle mission has evolved dramatically since the start of the program. As you’ll recall, during the heady days of the mid-1980s, most flights had a sort of “hop and pop” mission architecture. They would launch, immediately punch out a satellite or two, turn their attention to some smaller secondary payloads and experiments, and be back home in about a week. Fast forward to 1999 and flights are longer, more complex, and hardly ever see a satellite deployment anymore, other than small stuff like STARSHINE on the previous flight. And due to the gradual nature of these changes, it was easy to miss just how different things have become. I was surprised to realize that the last major satellite that we deployed on the shuttle was.. pause if you want to guess on your own.. TDRS-G on STS-70, back in 1995. And then you have to go back another couple of years to STS-51 with the TOS/ACTS deploy to find another one. Instead, most flights these days tend to fall into the categories of a) space station construction and servicing (be it Mir or ISS), b) Spacelab and SPACEHAB science flights, or c) deployment and retrieval of free-flyers like SPARTAN and SPAS. In the wake of the Challenger accident, the Shuttle’s role of the nation’s primary launch platform had fallen by the wayside and it had instead embraced its other strengths.
I bring all this up because today we’ll be talking about the deployment of the Chandra X-Ray Observatory, and the Inertial Upper Stage that will propel it into its lofty (and unusual) orbit. On this mission the primary deployment will take place just a few hours after main engine cutoff, and the crew will be back home less than a week after lifting off. It’s practically nostalgic.
But despite such a short flight, with such a standard template, we are going to have an awful lot to talk about. In fact, going by word count this is the longest episode of the show to date, close to doubling the word count in an average episode, which partially explains why it took twice as long to make. Anyway, I think we better jump right in. Let’s meet the crew.
Commanding the flight, in a historic first, was Eileen Collins. We know Collins from a couple of flights, most recently riding along with her as Pilot on STS-84, which delivered Mike Foale to Mir while bringing a grateful Jerry Linenger home. Of course, with this move from the right to the left of the cockpit, Collins becomes the first woman to command the Space Shuttle, to which I can only say it is about damn time. When asked how her young daughter felt when she’s at school and somebody points out that her mommy flies the Space Shuttle, Collins replied “Oh heck, my daughter thinks everyone’s mommy flies the Space Shuttle.” This is her third of four flights.
Joining Collins up front is today’s Pilot, Jeff Ashby. Jeffrey Ashby was born on June 16th, 1954 in Dallas, Texas, but grew up in Evergreen, Colorado, about half an hour west of Denver. He earned a Bachelor’s degree in Mechanical Engineering from the University of Idaho and a Master’s in Aviation Systems from the University of Tennessee 17 years later. In between those two stints in school, Ashby joined the United States Navy, becoming a Naval Aviator. During his time in the Navy he flew 65 combat missions over Iraq, completed six aircraft carrier deployments, and graduated from the Naval Test Pilot School and the Naval Fighter Weapons School. He was selected as an astronaut in 1995 and this is his first of three missions.
Throwing off the regular order, if we want to find Mission Specialist 1, Cady Coleman, we have to head down to the middeck, where she had the whole deck to herself. We know Coleman from STS-73, the US Microgravity Laboratory 2 flight, which took an incredible seven launch attempts to finally get off the ground. While we’ll hit a couple of scrubs on this mission, I’m sure Coleman was relieved that it took only three attempts for this flight. This is her second of three missions, but her final time riding the shuttle, with her third flight consisting of several months on the ISS, arriving and departing on a Soyuz.
Moving back upstairs, we find Mission Specialist 2, and a very familiar face, Steve Hawley. We first met Hawley all the way back in 1978 when he joined the first class of Space Shuttle astronauts, the Thirty-Five New Guys. Since then he’s flown four remarkable flights including the deployment of the Hubble Space Telescope, and a return to Hubble for its second servicing mission. With his flight today he marks his fifth and final trip into space, and the last flight of an alum from the first class of Shuttle astronauts.
Next to Hawley is Mission Specialist 3, Michel Tognini. This is actually Tognini’s second spaceflight, since he was one of several French astronauts to spend time on the Russian space station Mir. But since it’s his first time flying with us, let’s take a quick look at his biography. Michel Tognini was born on September 30th, 1949 in Vincennes, France. Tognini graduated from military school with a degree in advanced mathematics, and then enrolled in the French Air Force Academy. From there he served as a fighter pilot, flying the SMB2 and Mirage F1, before going to test pilot school in England. He was selected as an astronaut in 1985, training in Russia for a stint on Mir and learning to fly the Buran spacecraft. He launched to Mir on Soyuz TM-15 along with our old buddy Anatoly Solovyev, returning to earth two weeks later. This is his second and final flight.
And that’s it! Like I said, this is a flight that’s sort of in the mold of the early Shuttle missions, so not only does it have a short duration, but it also has a small crew.
The planned flight may have been short, but like most Shuttle missions, there was a long wait for it to get off the ground. STS-93 was originally scheduled to lift off nearly a full year earlier, in August of 1998. Some of the delays stemmed from delays in the ISS missions, but some also came from both the payload and its upper stage: our old friend the Inertial Upper Stage. The IUS, of course, is the workhorse kick motor that lofts payloads from a Shuttle-friendly low Earth orbit up to something much higher, usually a geostationary transfer orbit. In a stroke of bad luck, a classified missile detection satellite was lost in April of 1999 when its IUS malfunctioned during stage separation. This would necessitate a delay until the cause of the IUS issue could be determined, but also because the military took NASA’s IUS so they could look for clues as to what happened to the one that failed. This was further complicated by the fact that the investigation itself was classified, largely leaving NASA in the dark. But eventually the issue was cleared up, STS-93 got its IUS back, the payload was ready, and everything was rolled out to the pad.
On July 20th 1999, thirty years to the day after Apollo 11 landed on the moon, Space Shuttle Columbia was ready to lift off on yet another mission. In the final seconds of the countdown, the sparklers at the base of the stack were lit, burning off any excess hydrogen wafting near the pad in the moments before main engine ignition. But at nearly the last moment before SSMEs fired up, the ground called a hold. An instrument that measured the levels of hydrogen in the Shuttle’s aft engine compartment had noted a reading that was out of bounds, and at T-8 seconds the ground controller responsible for monitoring the hazardous gas levels called for a hold.
This was perhaps a little overly cautious, especially given how risky it can be to potentially have an RSLS pad abort, but hey, better safe than sorry. Unfortunately, the reading turned out to be erroneous, so it would have been safe to proceed after all. The hydrogen levels were monitored using an instrument that was generally pretty reliable, but that was also known to occasionally experience what is delightfully called an “ion-pump-burp". Basically, the instrument leaks a little bit of the hydrogen it was just measuring and mistakenly measures it a second time, resulting in a spike in reported levels. The spike passed quickly, but with only seconds to go in the countdown, it was too late. Scrub for the day.
Two days later, everyone got ready to do it again, only to be denied by the presence of lightning inside the safe radius around the launchpad. Another scrub. Finally, on July 23rd 1999, at 12:31 AM Eastern Daylight Time, Space Shuttle Columbia lifted off for the 26th time… and right away things started to go wrong. I should mention that while as usual I pulled from a number of sources, one source that was particularly helpful for this next section was a series of blog posts by a regular on this show: former Shuttle flight director and program manager Wayne Hale. I even got the episode title from a comment of his in one of the posts. I’ll be sure to link to Hale’s blog posts on the show notes page if you’d like to read his recollections of this incident, which I definitely recommend.
The fact that a loose cable in the right-hand SRB thrust vector controller resulting in erratic reports of low pressure in its hydraulic system is not the craziest thing about this ascent is illustrative of just how wild it really was. We’re not even going to talk about it other than that one mention.
About five seconds after main engine ignition, one second before liftoff, several values on mission controllers’ screens shifted in a small but consistent way that indicated something serious was going on with main engine number 3, on the right. No one knew it at the time, but Columbia had basically just shot itself with a golden bullet and was now bleeding hydrogen. But to explain that, we need to take a step back.
This is partially rehashing ground covered in Episode 156, STS-78, so I’ll be a little brief, but we need to talk about some of the inner workings of the Space Shuttle Main Engine. If you were to peer up into the engine you would see the main combustion chamber, a surprisingly small volume where hydrogen and oxygen are mixed and burned before being expelled through the throat of the engine and out the back, propelling the vehicle forward. At the top of the main combustion chamber is the injector plate, which basically looks like a big shower head, with hundreds of little holes in it. It is through these holes that hydrogen and oxygen are sprayed in an extremely precise fashion, resulting in the desired mixture, resulting in smooth combustion with the desired properties. If you were to inspect one of these holes you would see that each one is actually two holes: a central hole for oxygen, and then around that central hole is a donut-shaped one for hydrogen. The analogy I used last time we talked about this was sticking a thin straw down the center of a thick straw, and I still like that comparison. Check the show notes page for a photo.
The thin straw in the middle channels liquid oxygen from a highly pressurized cavity that is supplied by the high pressure oxidizer turbopump. This thin inner straw is called a LOX post, and if one were ever to break off and enter the main combustion chamber it would be a Very Bad Day. So when a LOX post starts to show signs of wear, it’s plugged shut on the top with a gold-plated pin, preventing liquid oxygen from entering it. We discussed this on STS-78 because on that flight enough LOX posts were pinned that it actually threw off the mixture ratio and caused some other problems. Today we’re discussing it because.. the LOX post pin is the golden bullet that Columbia accidentally shot itself with.
The pin itself actually is sort of vaguely bullet sized, measuring around 23 millimeters long and around two-and-a-half millimeters in diameter. Somehow the pin worked itself loose and was propelled down the LOX post by the high pressure oxygen behind it, exiting into the main combustion chamber at a high velocity, just like a bullet being propelled down the barrel of a gun. Now, if I have this right, this had actually happened 17 times in the past with no problems, but I’m not 100% on that number so please take it with a grain of salt. Every other time, the pin just flew right out the back. Not this time.
Traveling at around 30 meters per second as it exited the LOX post, the pin first ricocheted off the interior of the main combustion chamber, leaving a dent but thankfully nothing more serious than that. After bouncing, it continued on, accelerated by the bonkers power of the Space Shuttle Main Engine, passing through the engine throat and impacting the side of the nozzle, the engine bell, at around 260 meters per second. For those metricly-challenged out there, that’s nearly 600 miles per hour.
Now, those who remember the structure of the main engine will likely see the problem we’re about to encounter. The interior walls of the engine nozzle are not just inert metal, they are an integral part of the engine’s cooling system. Lining the walls of the Shuttle main engine are over 1000 thin tubes through which liquid hydrogen at cryogenic temperatures is pumped, taking a detour on its way to the main combustion chamber. The frigid liquid hydrogen keeps the walls of the engine cool enough to withstand the immense heat and pressure generated by the engine. When the pin struck the nozzle on STS-93, three of these tubes were ruptured, about 71 centimeters from the bottom of the engine bell. If it had been five tubes, the wall of the engine likely would have failed, leading to a catastrophe, but it was only three.
Later calculations would show that the chances of a loose pin hitting the nozzle was around 1 in 4, and the chances of it rupturing one of the tubes was around 1 in 10, so today was just the unlucky day.
The rupture was downstream of any instrumentation that measured propellant flow. So from the onboard computer’s point of view, it was pumping the correct amount of hydrogen and oxygen into the engine. But the computer didn’t know that around one and a half kilograms per second of that hydrogen was leaking through the ruptured tubes and never making it to the engine. However, the onboard computer is pretty smart, and it did notice that the combustion chamber pressure was lower than expected. In order to correct this, the computer slightly raised the amount of liquid oxygen that was being pumped into the engine, restoring chamber pressure. It also made the engine run slightly hotter, which was one of the first clues later as to what had happened.
With the computer adjusting the flow of propellant, SSME number 3 was keeping up with the required thrust, but it was using oxygen at a slightly faster rate than expected. And actually, it was using oxygen fast enough that if nothing changed, Columbia would come up short and not achieve orbital velocity. All of this happened before the spacecraft even got off the ground.
One second after the leak began, Columbia lifted off, and five seconds after that, ground controllers got their next nasty surprise; one which got a lot more immediate attention than the somewhat subtle engine leak. Along the port side of the Orbiter, underneath the payload bay, was a long electrical wire. The wire happened to be positioned on top of a screw that due to wear and tear over the years had a small jagged burr on it. Over time vibrations had caused the wire to rub up against this sharp spot, wearing away the insulation and then, five seconds after lifting off today, allowing the electricity inside to arc to where it wasn’t supposed to go: in other words, a short circuit. Specifically, a 440 millisecond short circuit on phase A of AC bus 1, that is, one of the systems for distributing alternating current to various systems around the Orbiter. This affected a number of systems, but one way this problem manifested was Fuel Cell 1 getting confused and reporting high pH, which was immediately relayed down to the ground by Commander Collins since this had the potential to be a catastrophic problem. Unhappy fuel cells have a nasty tendency of mixing hydrogen and oxygen and, y’know, exploding. You can hear her call-out in the footage of the launch. The fuel cell problem ended up just being a false alarm, caused by the fluctuating electricity, but the short circuit did have some serious repercussions, and to discuss them we once again have to head back to the main engines.
Each main engine has a specialized computer that monitored its performance, issued commands, and kept things running smoothly. Each of these computers actually had two redundant controllers inside, called DCUs, or Digital Computer Units. With two units, DCU A and DCU B, one could fail and the other could carry on. When the short circuit happened, it knocked two of these DCUs offline: DCU B on SSME3, the right-hand engine, and DCU A on SSME1, the center engine. Knocking out DCU B on SSME3 meant that there was no more redundancy but was otherwise no big deal since DCU B was more of a backup than an equal partner. It didn’t send down nearly as much telemetry. So it wasn’t great that DCU A was knocked out on SSME1, the center engine. The ground got some telemetry, but were almost entirely in the dark as to the operation of the engine.
Not getting telemetry is irksome but not necessarily dangerous on its own. But it turns out that this time it made a real difference. During normal operation, DCUs A and B sort of compare notes and average out their readings, making it less likely that any one anomalous sensor will cause a big problem. DCU B on SSME1 happened to have a slightly high bias in its reading of combustion chamber pressure. Before the short circuit, this error was cut in half by averaging it out with DCU A but now that it was on its own, the error was more significant. The result was that the computer thought SSME1 was running at a slightly higher pressure than it really was. So despite actually running perfectly fine, the computer throttled the engine back just a little bit to get to what it thought was the appropriate chamber pressure.
So just to quickly review, cause that was a lot, here’s the situation just a few seconds into the mission. A gold pin has been fired out of SSME3’s injector plate, impacting the nozzle and rupturing three cooling tubes, causing a small hydrogen leak. SSME3’s computer, puzzled by a slightly lower than expected chamber pressure, increased the amount of oxygen it was pumping into the engine, raising the pressure back to the desired value.
At almost the same time, a short circuit caused by a chafed wire knocked a couple of engine control units offline, leaving SSME1 to be run by its DCU B. This DCU B happened to think the engine chamber pressure was slightly higher than it really was, so it got confused and throttled SSME1 down just a bit.
For the crew, a lot of this happened outside of their awareness. The AC Bus short certainly got their attention, but the engines took care of themselves, with folks on the ground mostly only aware that they were running on fewer DCUs than normal, and that it looked like they might have a small hydrogen leak on their hands. The only action the crew had to take during ascent was to disable some sensors on the AC bus lines. Normally these sensors would detect if the electricity was out of spec and shut the bus down to protect sensitive equipment powered by the bus. But with one AC bus already down it would be more dangerous to have this system encounter a problem and erroneously trigger, shutting down another bus. So the automated protection was disabled and instead, any faults would be handled manually by the crew, if they came up, which they didn’t.
Eight minutes and twenty-eight seconds after lifting off, Columbia’s engines shut down, with the vehicle safely in orbit. But MECO was a little different than usual this time. Right before the engines were supposed to shut down, four sensors in the external tank registered low levels of liquid oxygen and triggered MECO about one sixth of a second early. Columbia had run out of liquid oxygen, and the computer shut everything down before the engines could suck in vacuum instead of LOX and spin themselves apart. The very slightly early shutdown left Columbia with a 4.9 meter per second underspeed, well within the ability of the OMS engines to correct.
But what the heck? Running out of liquid oxygen early is really serious, even if it turned out to not be that big of a deal this time. What happened? Did they not load enough into the External Tank? Well actually, yes, they were a little light in the External Tank, but it was only a couple hundred pounds and that’s well within the margin of error for propellant loading. No, the reason they ran out early was the hydrogen leak caused by the LOX post plug rupturing the three nozzle cooling tubes. The hydrogen leak caused a slightly lower chamber pressure in SSME3, leading the computer to add more oxygen to raise the pressure back up. But actually, if you were to run the math, you would see that instead of a nice benign 4.9 meter per second shortfall, the hydrogen leak should have caused a much gnarlier sixty-one meter per second underspeed, which could have required an immediate abort of the mission, probably using the Abort Once Around procedure. So where did the extra oxygen that got them from a 61 meter per second shortfall to only 4.9 meter per second come from?
From SSME1! SSME1 had its own completely unrelated issue that caused it to very slightly throttle back, and thus use a little less oxygen! This.. is completely wild. The Space Shuttle Main Engines have a nearly spotless record. During the development of the Shuttle, the engines were what spooked people the most, so a ton of effort went into making them incredibly efficient and reliable, and as a result, they were borderline perfect. But here we have two engine problems on the same flight that are completely unrelated that essentially cancel each other out. In telling this story, it’s hard to avoid the word “miraculous”.
But as completely crazy as that coincidence is, don’t let it distract you from the fact that this is actually a big success story for the Space Shuttle Main Engines. If it hadn’t been for the Shuttle’s philosophy of redundancy, instead of talking about underspeeds at MECO, we would be talking about four of the scariest letters in a Shuttle astronaut’s vocabulary: RTLS, a Return to Launch Site abort. Which gives me another opportunity to remind you of the time that John Young was being asked what information he wanted on the displays during an RTLS abort and he said it didn’t matter because in the case of an RTLS abort he would be covering his eyes and screaming.
Reflecting back on this incident, and discussing how some modern spaceflight systems are sometimes doing away with extra redundancy, Wayne Hale wrote “Whenever I am engaged in one of these discussions I remember STS-93 where a 2 cent screw and a 10 cent length of wire demonstrated the vulnerability of an otherwise highly reliable critical system.”
But despite all that, there was no RTLS, there wasn’t even an Abort to Orbit. The engines shut down, the External Tank was jettisoned, and Commander Collins radioed down “It’s great to be back in zero-g again.” After the OMS-2 burn, Columbia was in a nice reasonable 268 by 285 kilometer orbit. And I checked, the OMS-2 burn was actually smaller than the one on the previous flight, so there you go.
Despite the nice radio message from Eileen Collins, the crew definitely knew something was amiss. In an oral history interview a few years later, Steve Hawley said that at MECO the crew could see that they were several miles away from the expected orbital insertion point, confirming that something had affected their trajectory on the way up. He said that despite the AC bus short, which could have been an extremely serious problem, there was not much concern from the crew, which surprised even himself. The simulation training drilled into the crew’s heads that the shuttle was an incredibly fragile system that would have failure after failure. But they knew that in reality, the systems were pretty robust and reliable, and the crew were well versed in the proper response to each potential problem. He said that as an astronaut you develop an instinct to the do the right thing, which isn’t the same thing as reflexively solving the problem. Sometimes doing the right thing is to do nothing at all, sometimes it’s just to grab the appropriate procedure book and start churning through it. It’s kind of an interesting attitude. I’ve always been impressed by how astronauts never seem particularly nervous about even life threatening issues. And based on comments from Hawley and others before him, it seems that this attitude stems from a confidence that the crew knows exactly what to do in response to any solvable problem.. and if it’s not a solvable problem, why get worked up about it?
Anyway, after a very eventful ride uphill, the crew were apparently unfazed, and got right to work. Which is a good thing, because as I mentioned, this is an old school style Shuttle flight. The crew were barely out of their seats when they began working on the deployment checklist. When you think about it, these early deployments are kind of strange. Hawley pointed out that it’s sort of the worst time to do a deploy. The crew is all amped up from the launch, they’re still getting used to weightlessness, and there’s just generally a lot going on. With each subsequent day the crew would be more and more comfortable and at ease. He speculated that this timeline that was so common in the early flights reflected a lack of confidence in the Orbiter. Back then it seemed much more likely that a mission might hit a snag a day or two into the flight and have to come home early, carrying the hapless payload back to Earth to hopefully launch another day. If the deploys were done a few hours after launch, then a fuel cell concern on day 2 or a GPC problem on day 3 couldn’t possibly affect it. At this point in the program there was a lot more confidence in the overall Shuttle system, but I guess someone decided “hey, the IUS procedures are already written up, why mess with success?” so here we go.
Around five and a half hours into the mission, the Chandra X-Ray Observatory and its upper stage were tilted up to a 58 degree angle, the deployment attitude, and umbilicals were severed, marking the point of no return. But before we send this newest space telescope on its way, we have to take yet another trip back in time, this time heading back 22 years when work on this project initially began.
In 1977, early work for what was then called the Advanced X-Ray Astrophysics Facility were underway. Now, don’t get the wrong idea, they didn’t spend 22 years physically building this thing, that only took five years. The first few years of any project like this consists of a lot of gathering requirements, determining broad strokes of the technology, generally answering at a high level what this thing is and how it will work, and getting through review after review while writing mountains of documentation. But still, by the time the observatory was deployed, someone somewhere had been waiting decades to see it arrive on orbit.
Let’s start with the basics: How did the Advanced X-ray Astrophysics Facility come to be known as the Chandra X-Ray Observatory? This one’s easy. In December of 1998, the spacecraft was renamed in honor of noted solar physicist and Nobel prize laureate Subrahmanyan Chandrasekhar, who went by the nickname Chandra. Chandra had passed away in 1995, but his robotic surrogate would continue his astronomical work.
OK, with the name out of the way, what is the Chandra X-Ray Observatory? Well, as you may have guessed, it’s an observatory.. for X-rays. Specifically, it’s one of the four Great Observatories, joining the Hubble Space Telescope and Compton Gamma Ray Observatory which we are already familiar with. The fourth will be the Spitzer Space Telescope, which focused on the infrared part of the spectrum and which will launch in 2003, but since that launched on a Delta II it won’t enter our narrative directly. So Spitzer would eventually cover infrared, Hubble covered visible and ultraviolet, Compton covered high energy X-rays and gamma rays, and once we deploy it, Chandra will cover lower energy X-rays. With their powers combined, scientists could observe the universe in a huge swath of the electromagnetic spectrum.
Thanks to our nice thick atmosphere, X-ray astronomy is not possible from the ground. This might be a hassle for curious scientists, but we should be glad, since getting X-rayed all day every day wouldn’t be great for.. living. So because X-rays can’t pass through the atmosphere, observing X-rays from space has always been a top priority for astronomers. For that reason, this is not the first space-based X-ray observatory, but it will be orders of magnitude more sensitive and sophisticated than its predecessors.
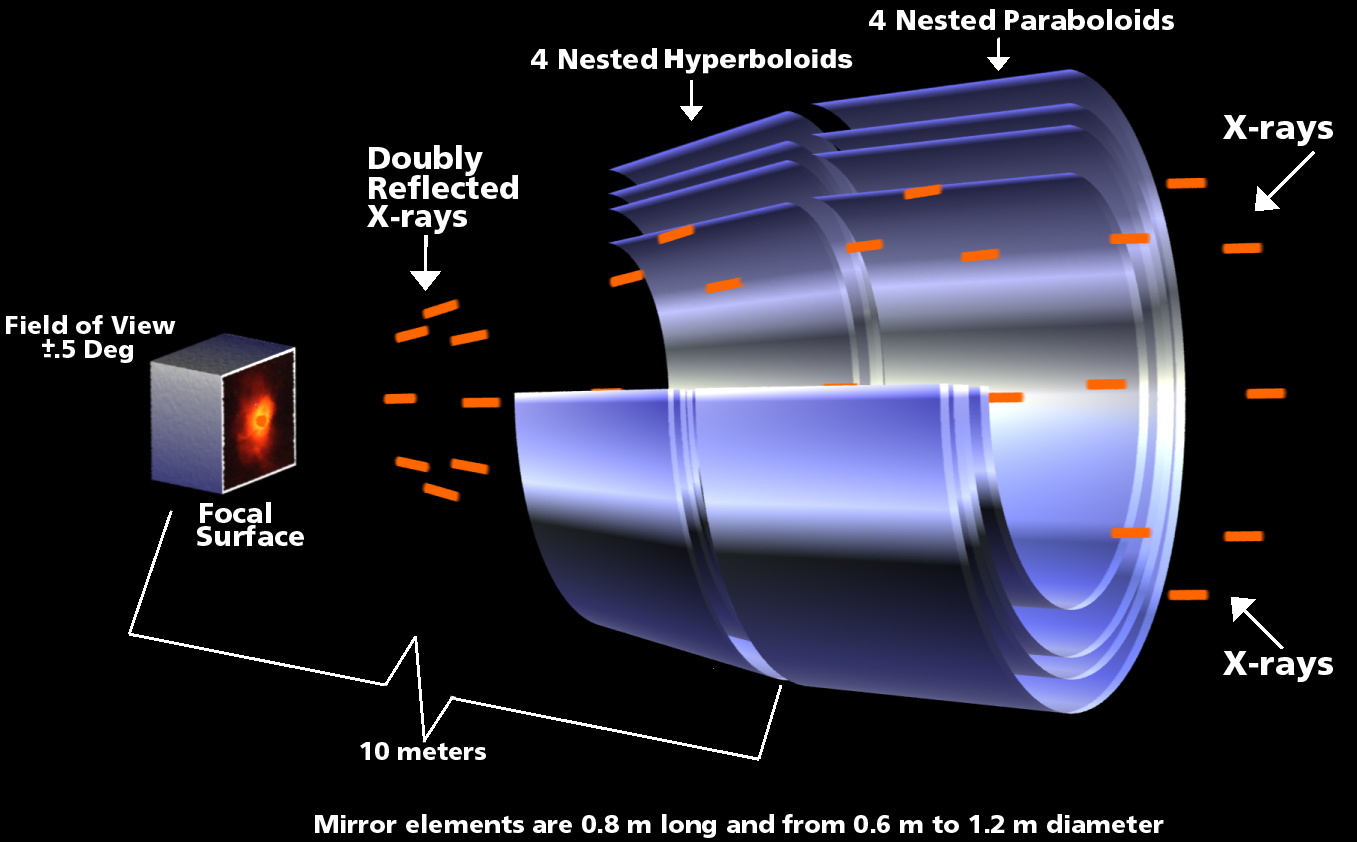
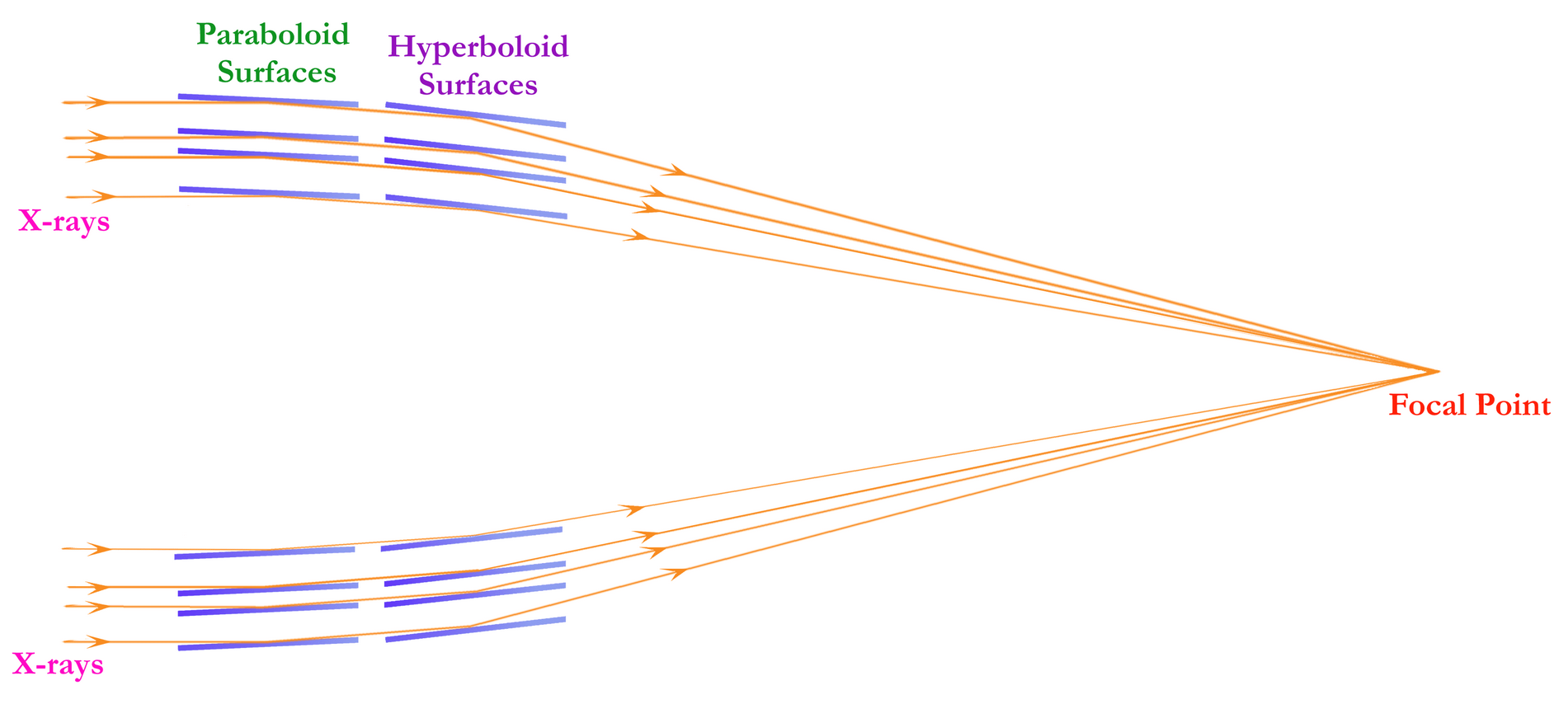
Making an X-ray telescope is a tricky business. You may recall from the episodes covering the Hubble Space Telescope that its light is collected by a large mirror, which reflects and concentrates the light onto a smaller mirror, which then directs the light into a variety of instruments. But X-rays don’t really want to bounce. They tend to either get absorbed, or just go right through the thing that’s in their way. It’s why they’re used in medicine: they go right through skin and muscle, but are absorbed by bones, allowing your doctor to see just how badly you messed up your leg trying to learn parkour. So rather than a big mirror that’s essentially perpendicular to the incoming light, forcing it to completely reverse directions twice like Hubble, Chandra sort of gently guides the X-rays where it wants them to go. A decent analogy for this process can be seen in a particular episode of the TV show Mythbusters, where Adam and Jamie are, for whatever reason, trying to make a bullet bounce off of several flat surfaces and return to the person who fired the gun. They started out with three metal plates, which would each force the bullet to take a 90 degree turn, tracing out a square. They quickly discovered that the bullet mostly just splattered on the first metal plate and whatever made it to the second plate was going much slower than when it left the gun. So they tried adding a few more metal plates at slightly shallower angles, and the bullet fared better, but still struggled. Then, they essentially did calculus in the real world, and switched from a series of flat plates to one long curved surface, which guided the bullet gently enough for it to complete the full circle back to the shooter. And that’s exactly what Chandra is going to do. The bullet is the X-ray, and the curved metal is the mirror. But instead of sending the X-ray back to where it came from, the mirror will guide it into the observatory’s instruments.
The result is a funky shape called a grazing incidence mirror. It looks less like a mirror and more like a short tapered tube, or maybe a weirdly squat funnel. Then, to catch as many X-rays as possible, there are three more of these funky tapered tubes, all inside each other, creating an appearance of concentric circles when you look at it from the front. It’s sort of a Russian nesting doll of metal tubes. Just to further complicate things, these four tapered tubes actually lead into another set of four tapered tubes, which are tapered at a different angle. So really, it’s eight of these paraboloid and hyperboloid shapes, all carefully ground and polished, and coated in iridium, gently guiding the X-rays towards the scientific instruments. The outermost mirror is about 1.2 meters across, and the whole mirror assembly is around 82 centimeters long. For a sense of scale, the mirror assembly is a little bigger than a typical laundry washing machine.
Together, the mirrors add up to 950 kilograms, around 16% of the mass of the entire spacecraft. Fun fact, the mirrors were made in the same place as the Hubble mirrors, but don’t worry, they tested these ones.
The mirrors focus the incoming X-rays to a point ten meters back in the spacecraft, where they could be analyzed by Chandra’s two scientific instruments: a high resolution camera, and an imaging spectrometer. These two instruments each had strengths and weaknesses that were balanced out by the other instrument. The high resolution camera, as you might guess, was able to precisely determine where on the sensor the X-rays hit, allowing for X-ray photography. It did this by using super tiny lead-oxide glass tubes that were about 1.3 millimeters long and about one eighth the width of a human hair across; 69 million of them. When an X-ray hit one of these tubes it would dislodge some electrons, which were then attracted to the charged backplate of the sensor. On the way down, the electrons would dislodge more electrons, creating an avalanche, which the sensor would then detect. It’s the same sort of tech used in stuff like night vision goggles, amplifying the low signal of single photons coming in. The tradeoff was that it was not able to determine the energy level of the X-ray, essentially its color. But hey, we’ve also got the imaging spectrometer! It wasn’t as precise about where, exactly, the X-ray hit the sensor, but it could determine the energy level. By using both instruments, scientists could see visual images of where the X-rays were most intense, and also what energy levels those X-rays were. Giving this information to clever scientists unlocks a pretty incredible amount of information about stuff that’s being observed from billions of light years away.
That description covered two of the three main subsystems of the observatory: the telescope subsystem, and the science instrument module, along with the long empty cylinder that connected them. Returning to the front of the spacecraft, around the opening to the telescope, we find the spacecraft subsystem. This was the part that had a propulsion system for changing its orbit, an attitude control system for pointing at astronomical targets, communications systems for talking to the ground, computers and data storage for processing the scientific data, and two seven-and-a-half meter long solar arrays for electricity.
Together, we end up with an observatory that’s 11.8 meters long and with a mass of 5,865 kilograms. Throw on the Inertial Upper Stage and we get 17.4 meters in length, and if you include the support equipment, it comes out to 22,753 kilograms. This means that if we don’t count the unknown mysteries of the few classified payloads, Chandra is the heaviest and longest payload carried in the entire Shuttle program. At 17.4 meters in length, it was less than a meter shorter than the payload bay itself, which explains how Columbia got the privilege of carrying the observatory to space: it was the only Orbiter that hadn’t yet had its airlock moved from the middeck out into the payload bay.
So now that we have a little more appreciation for what it is we’re about to deploy out of the payload bay, let’s fast forward back to the Mission Elapsed Time of 7 hours, 16 minutes, and one second, where Mission Specialist Cady Coleman has been waiting patiently for us to finish our little history lesson and let her deploy the spacecraft. Coleman finished the checklist, Chandra was released, and springs gently pushed it up and over the crew cabin, marking the final significant satellite deployment from the Space Shuttle. Commander Collins then gently nudged Columbia away from the observatory and once at a safe distance performed a larger burn to open up a large gap between the Orbiter and Chandra. Like with all IUS deploys, she then turned the belly of the Orbiter toward the observatory, protecting the windows from any nasty residue or potential debris resulting from the IUS firing.
Around an hour after the successful deployment, the first stage of the IUS fired, completing its job in two minutes. It then dropped off and allowed the second stage to fire for another two minutes, leaving Chandra in its initial orbit, with a perigee of 327 kilometers and an apogee of 72,067 kilometers. After firing its own propulsion system in a series of burns spaced out over 15 days, the Chandra X-Ray Observatory ended up in its final orbit, roughly 10,000 by 140,000 kilometers, over a third of the way to the moon.
Wait, what? that’s a crazy orbit! It’s not even a geostationary transfer orbit, since its apogee is twice as high as the GEO ring. That’s because Chandra isn’t going to GEO. It was actually originally going to be a low Earth orbit mission, serviceable by the Shuttle like Hubble, but it turns out that’s actually pretty difficult and expensive to do. Plus, keeping a spacecraft in LEO comes with its own sets of tradeoffs. For a big chunk of every revolution, the Earth is going to get in the way of whatever you’re looking at. You’re also constantly flip flopping back and forth between night and day, which causes challenging thermal problems. For an example, look no further than the early days of Hubble, when the transition between night and day would cause vibrations that threw off observations and actually damaged some of the structure. There are a few other issues but I think you get the point.
So if LEO is no good, why not GEO? Well, GEO has its own set of issues. For one thing, slots in GEO are in high demand and there’s no real reason for Chandra to be there. Plus, staying in GEO isn’t like the two-body Keplerian problems from the textbooks. Real world perturbations would pull the observatory out of its slot unless propellant was used for stationkeeping burns.
So instead, with apologies to any Chandra flight dynamicists who likely spent years defining this orbit, we seem to be just be going to a somewhat arbitrary but nice big benign orbit that’s convenient to get to. What’s nice about this orbit is it’s got a long period, taking around 63-and-a-half hours to go around once. Compare that with the one-and-a-half hours of Hubble’s orbit. With such a long orbital period, Chandra could stare at a target for long amounts of uninterrupted observation time. What luxury.
The Chandra X-ray Observatory was designed for at least a five year mission and at the time of this recording it’s at 24 years and counting, shedding (or collecting) new light on high energy processes in the universe. Pretty cool.
OK, wow, that was a lot of stuff to talk about and we’re not even eight hours into the mission. What else is going on with this flight? Honestly, not a ton. With Chandra and its IUS being so heavy, weight savings were paramount on this flight, so there’s not a lot of secondary stuff up in the middeck, but there are still some odds and ends. One of our favorite secondary payloads, SAREX, the amateur radio experiment, flew again. I didn’t get any fun stories out of it this time, but the crew spent some time chatting with several schools on the ground as well as some lucky amateur radio operators all around the world.
The pilot crew also tested out a thruster firing technique that would be used on the upcoming STS-99. On that mission we’ll be extending a 60 meter long boom with a radar instrument on the end and it was important to learn how to do this and still maintain Shuttle attitude while minimizing disruptions on the boom. 60 meters is a lot of leverage, so any attitude adjustments would have to be made carefully and delicately. To make sure that the new software for achieving this worked, the STS-93 crew put it through its paces on this flight.
The crew also tried out the ISS-bound treadmill we’ve seen fly a couple times now. The space station treadmill is one of these pieces of equipment that I think would be easy to overlook but is both incredibly important and deceptively difficult. Long duration crew members needed a dependable way to exercise every day, giving their bones and their cardiovascular systems the workout they weren’t getting otherwise as they floated throughout their day. But the rhythmic pounding of the crew member’s feet on the treadmill had the potential to build up dangerous harmonic resonances on the station, which could build and build until something snapped. Just look to the flapping solar arrays on Mir for proof. So today’s crew would not only be testing out the treadmill itself, but also its vibration isolation system. By letting the treadmill float freely, vibrations from running would not be conveyed to the greater structure. But you can’t just let it float wherever because it would wander around the cabin and it would be a little weird for the crew member running on it, as the running surface was at a slightly different angle and position every time their foot struck it. So in addition to vibration isolation, it also needed to handle stabilization.
The treadmill and its vibration isolation and stabilization system seemed to work fine, but unfortunately, a digital video camera that was being used to collect data failed, meaning more data would have to be collected on a future mission. Ah well, at least they got the crew’s impressions.
Lastly, there actually was a whole other telescope on Columbia that I have yet to mention: the Southwest Ultraviolet Imaging System, which goes by an acronym that I’m going to pronounce as “Swiss”. SWUIS got its name because it was being flown for the Southwest Research Institute, and was, as you may have guessed, an ultraviolet telescope. Fun fact, the principal investigator was Dr. Alan Stern, who would later go on to become the principal investigator of the New Horizons mission to Pluto. This experiment was essentially a little digital camera and telescope that was plunked onto the round window at the center of the crew hatch down on the middeck. As you’ll recall, this window was unique among the eleven windows in the orbiter since it was the only one that lacked an ultraviolet filter, which enabled experiments just like this.
Operating SWUIS was Steve Hawley, which makes sense since in addition to being an astronaut, he was also an astronomer. Just an “astro” kind of guy, I guess. Throughout the mission, Hawley used SWUIS to observe several planets in the solar system, recording their UV emissions, something that’s not possible from the ground. Talking about the experiment in an oral history interview he said that the experiment was challenging and extremely time consuming, but it was fun since it was really hands on astronomy. If you’ll recall the layout of the middeck, you’ll notice that the crew hatch was right next to the waste collection system. So with Hawley camped out at the hatch, embedded in a “rat’s nest” of cables, for most of the mission, Commander Collins joked that she never saw Hawley leave the toilet.
While we’re hanging out with Steve Hawley, I thought I’d mention a few more observations he had, not of the planets, but of his fellow astronauts. This was Hawley’s last mission, and the oral history interview was actually a few years after that. And since he was there from the very start of the Shuttle program, he brought a perspective that not many astronauts had. While being careful to not call into question the skills and dedication of his younger colleagues, he noted that even by the late 90s they lacked the same intimate knowledge of the underlying systems that the class of 1978 had. When the TFNGs arrived, there was no Space Shuttle. There were no procedures. It was all still being figured out. So they had no choice but to learn how the systems worked and develop the procedures themselves, from the ground up.
Because of this, the early crews not only knew what to do, they knew why that was the thing to do. They understood the underlying systems and just used the procedures as a reminder or as a shorthand. Newer crews absolutely knew their stuff, but their knowledge of why that’s the way it’s done was not as robust. It reminds me of a joke I’ve seen floating around the internet in a few different forms, that I’m just going to quickly summarize. A woman was cooking a roast for dinner, but before putting it in the oven she cut the ends off. Her kids asked her why she did that and she said that’s just the way her mother taught her how to cook a roast. So the kids ask their grandmother why the ends need to be cut off. The grandmother says it’s because when she learned how to cook they had a very small oven and if you didn’t cut the ends off, the roast wouldn’t fit! So the procedure still worked, but its limitations no longer applied and the underlying logic had been lost to time.
Hawley said that NASA needed to come up with a better way of handing down that complete knowledge from generation to generation, so the same mistakes aren’t made and the same lessons don’t need to be relearned. He said, “I mean, in the same sense that the astronauts today probably don’t know why this procedure is written the way it is. They just know when this happens, this is what you do, because they weren’t involved in developing it. In the beginning, we didn’t know what to do when this happened, so we had to figure it out. Now it’s written down, so you just learn to do it. What happens when things begin to break thirty years later that you didn’t really think about, and now you don’t have the expertise anymore, and you don’t remember why they built it that way, you don’t know remember why you rendezvous with Hubble at night, that sort of thing.”
Hawley didn’t have any solutions readily available, but it was an interesting observation. And the idea of understanding the underlying reasoning to avoid the same mistakes is especially interesting given that this interview was performed on January 14th, 2003, just two days before Columbia would lift off on its final, doomed, mission.
But that sad day was still nearly four years in the future. For now, the crew enjoyed their few remaining days on orbit, but just as their bodies were getting used to weightlessness it was time to head home. After an uneventful reentry and landing, Columbia landed at the Kennedy Space Center and closed out a mission lasting 4 days, 22 hours, 49 minutes, and 36 seconds.
STS-93 has sort of a mixed legacy. On the one hand, it will forever be known as one of the scariest close calls of the entire Shuttle program, and the revelation of faulty wiring lead to a stand down of the Orbiter fleet for five months as inspections and repairs were completed. But on the other hand, it safely delivered the Chandra X-Ray Observatory to orbit, where at the time of this recording it is still happily collecting unique observations and furthering our understanding of the universe, 24 years later.
One thing is absolutely sure. STS-93 is one of the most fascinating missions we’ve seen yet, and it will always be a favorite of mine.
Next time.. from one observatory to another, on STS-103 we return to the Hubble Space Telescope for the third time.
Ad Astra, catch you on the next pass.